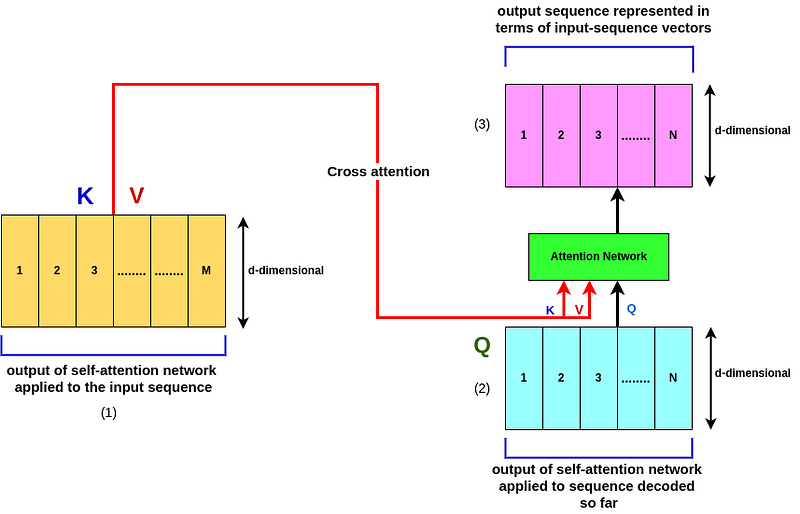
So at the top of our Encoder, we will get an output sequence of M d-dimensional vectors corresponding to the original M input words. These M vectors are gonna be the Values and the keys to the attention network of the Decoder. On the other hand, the decoded sequence (output sequence at the bottom decoding network) would be the Query for the decoder attention network! So if we have decoded N words up to this point (Q), it means that we have N d-dimensional vectors corresponding to the N words that we have decoded thus far, right?
So the reason this is called Cross Attention is that the keys and values are coming from the M words that have been encoded at the top of our Encoding network then the Query is coming from the N words that have been decoded thus far! So cross attention is used because the keys, values, and queries are coming from different sources! (1) 🔀
Whenever we do such architecture, we get a new encoding of the d-dimensional N Vectors at the end of queries which represents a new sequence of N words! (2). In summary, the initial N-words that have been encoded thus far are represented as the Values and keys via the attention mechanism which are at the top of the encoding of the input sequence, and the queries are coming from the N decoded words via the Decoder (Cross Attention) (3).
Ya, remember I mentioned putting softmax at top of our network would help to force the output falls between[0,1]? But such an approach has one big down point! 🤦♀️ That is it will tend to focus on a single element which is a big limitation! You ask why⁉️ Because we should keep several of the preceding words in mind when predicting since the overall target is to predict the potential next sequence of words, and the softmax just robbed us of that! This is a problem for the model. The solution to this problem is to have several different instances of attention/heads running at once! This lets the transformer consider several previous words simultaneously when predicting the next set! And that’s the intuition beyond using multi-head attention!
Multi-head attention is basically a generalization of the Attention Mechanism that we’ve seen before (refer to Attention Mechanism).
So now I’m going to present a Functional form for the Attention Mechanism, which states that Attention is a function of Query Q, Keys K, and Values V, correct? 😉 →→→ output = Attention(Q, K, V)
As we discussed earlier, the Query, Keys, and Values all are d-dimensional vectors, right? (1)
Now consider the iᵗʰ query or the iᵗʰ one of these n vectors (1), what we’re going to do is do a projection. You’ve never heard of Projection? Well, we essentially multiply that d-dimensional vector qᵢ times a matrix, which is formed of K rows, each of which is likewise d-dimensional, to get a projection of that query qᵢ(qi is a vector, it’s d dimensional, and it corresponds to the ith one of those n vectors, 1, 2, N).
Because adopting such a multi-head system increases the computational burden! 🤦♀️ Computing attention was already the bulk of the work, and we just multiplied it by many heads we want to use, ain’t it crazy? 🤯 We employ the method of projecting everything into a lower-dimensional embedding sub-space to get around this. This may decrease the matrices involved, resulting in a significant reduction in computing time!😁☀️