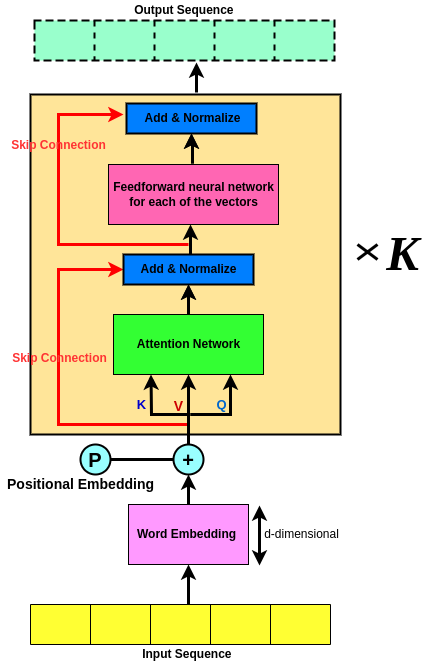
Let’s first recap the so-called Transformer network;
Going thro all of the above steps, we were able to Encode a sequence. Now if we did it one time, there is no reason to not do it K time! Where in practice K is 3 or 6! So we can repeat the process K time which possibly makes it a Deep Sequence Encoder that tends to improve performance!
Thus far we have talked about Sequence Encoder and the way it works for predicting the next word in the sequence! But imagine a situation where we not only wanna predict the next word but we wanna predict the next sequence of words! not just one word!
Take Translation from one language to another as an example. So here we gotta not only decode the original sequence but also need to decode it to another language and try to understand the same architecture in another language, right? For instance, consider “the orange cat is nacho” in English and ya wanna translate it into French. If so, based on what we’ve learned so far, we first need to Encode the English sequence;
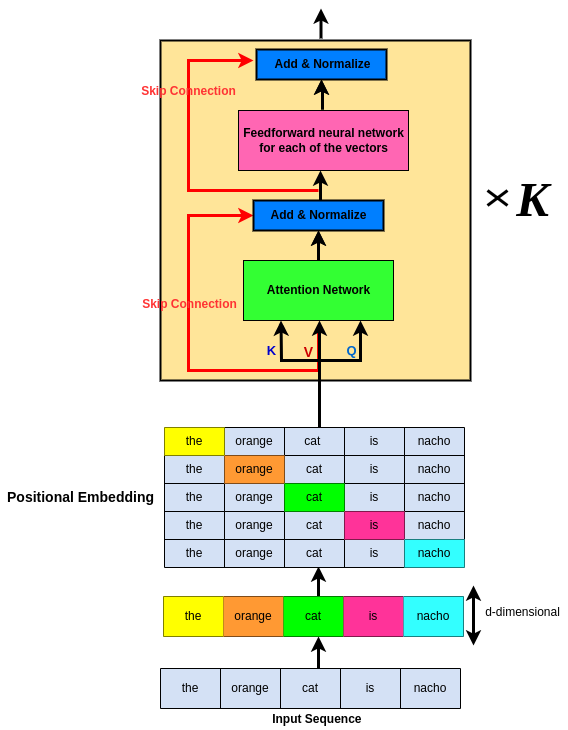
Okay! We have encoded our sequence, but what about French version of the sequence? shouldn’t we decode the gained knowledge into French?
Yes, we should! The way we’re gonna do that Decoding (2) ****for the entire sequence, has ALOT in common with what have learned so far (1)! See below to figure out how!
The mix of sequence Encoder to Decoder is shown in the picture below; Take a look at it, think 🧠 for a sec then come back and read the rest!
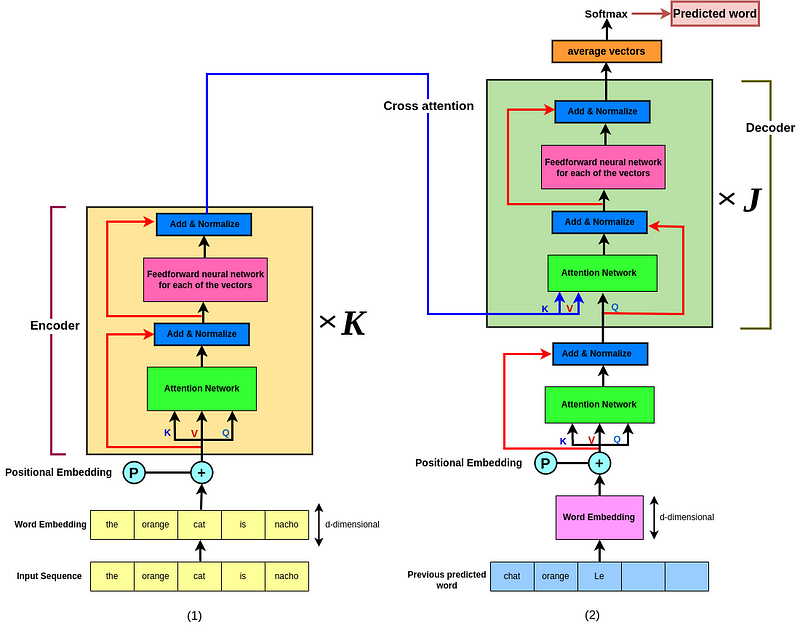
At the bottom of the decoder is the words that have been predicted by the decoder so far!
Now, what we’re gonna do is to take the last word that we predicted and use it as the input to the decoder then produce the french version of one word after the other! For instance, imagine we have predicted: “the” and “orange” in french (M words). So at the bottom, there are the M words that have been predicted so far. Therefore, on the left (lime box) is the original sequence and on the right (blue box) is the sequence that we have predicted say in french.
Now in the same concept, remember that I mentioned repeating K produces a deep network? Well if we did it for the encoder, then there is no reason to not do the same for the decoder as well! So on the right we gonna do in J times! So we have a repeat of k times on the left and J times on the right, right? This is called a deep architecture network!