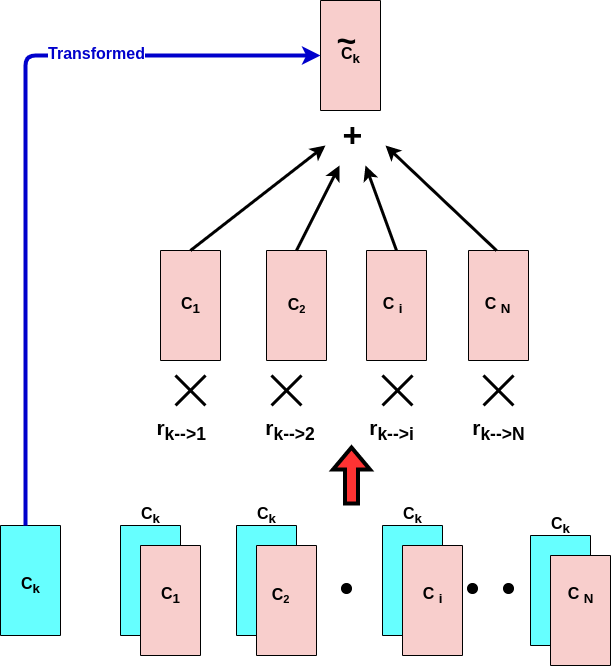
As you saw through this attention process, the original naive vector or Ck transformed to a new vector ~Ck which takes into account the context of surrounding words! (Ck → \~Ck). This way, Ck attends to the N code to which it is most correlated as implied thro the underlying inner product between word K and all the other words in the sequence, right?
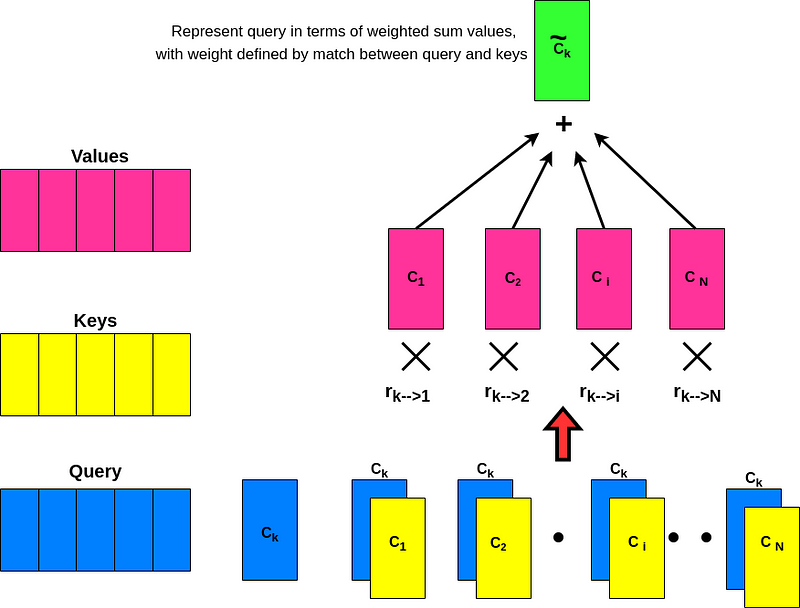
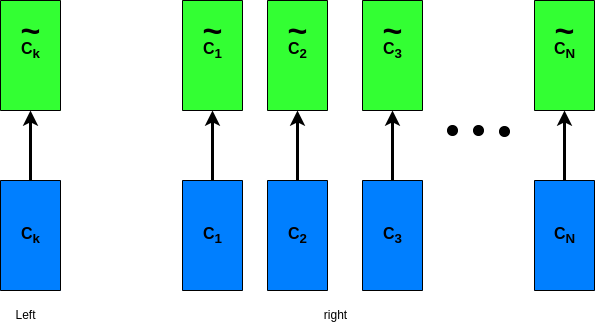
So till now, we were able to transform the initial naive vector Ck to a refined vector ~Ck which takes into account the context of the surrounding words. Then if we do it for one word (left), we can do it for all the words in the sequence (right). So now ~C1 takes into account the context associated with all other words in the sequence to ~CN. is to multiply each value vector by the softmax score (in preparation to sum them up). The intuition here is to keep intact the values of the word(s) we want to focus on, and drown-out irrelevant words (by multiplying them by tiny numbers like 0.001, for example). Final step **is to sum up the weighted value vectors. This produces the output of the self-attention layer at this position (for the first all the way to the last word).
But as ya may notice, this process is independent of the Order of the words! In other words, if we permute or re-order the words in a way that for exp. the last word becomes the first word, the output of this attention process will be the same! It means that the order of the words does not matter in this scenario! However, in the case of our Natural language, the order of the words matters! This is because it affects the contextual meaning! For example, if we have a sentence like this:
So we need to modify the current design in a way that takes into account the order of the words! But before jumping into this.
Before getting into the solution which takes into account the order of words, let’s introduce a new concept called Skip Connection!
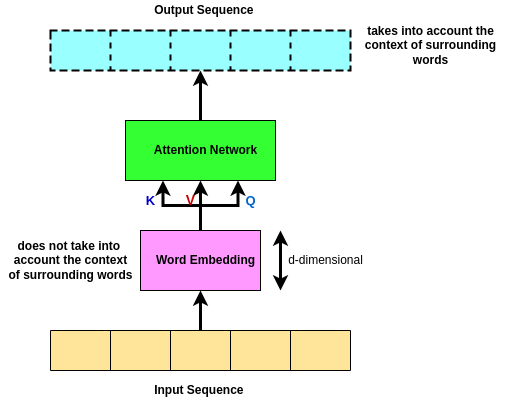
So in the original setup (diagram above), when you go from bottom to top (from input to output) when we do the attention network and we get the output sequence, we have lost the original word embeddings at the bottom! So what it does is; it takes the original word embeddings and it skips it above the attention network. Then what we do is we add the original word embeddings to the output of the attention network and after we have done this, we normalize them concerning each other!
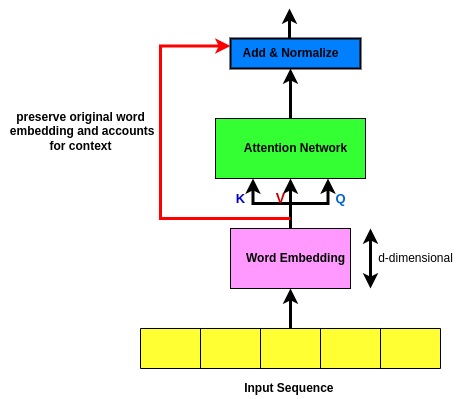
The main goal of Skip Connection is to preserve the original input sequence! 🌱 Ya ask why? This is because even with a lot of attention heads, there’s no guarantee that a word will attend to its position! The attention filter can forget entirely about the most recent word in favor of watching all of the earlier words that might be relevant. A skip connection takes the original word and manually adds it back into the signal so that there’s no way it can be dropped or forgotten. This source of robustness may be one of the reasons for transformers’ good behavior in so many varied sequence completion tasks! 😎Skip connections in deep architectures, as the name suggests, skip some layer in the neural network and feed the output of one layer as the input to the next layers (instead of only the next one). In general, there are two ways that one could use skip connections through different non-sequential layers: