Let’s first summarize what we learned so far; 👩🏫assume that we have N words with C(N) associated vectors. Then we take the inner product between those vectors which is a measure of similarity between word vectors. And if it’s + then ****two given words are similar, if — then words are dissimilar, right?
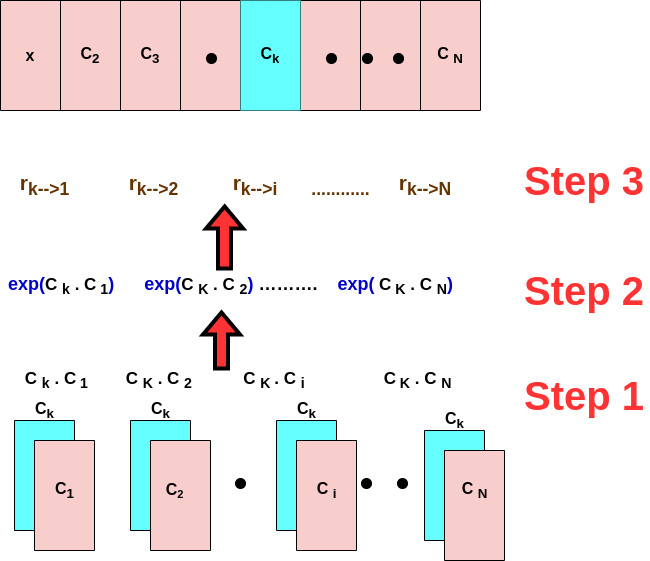
Okay!💆♀️ Then what we gonna do now is to quantify how similar “ALL” words are to Word K. (instead of just quantifying two specific word thro dot product concept, we go for ALL words in the sequence).
This means that we wanna quantify how similar every word in our sequence is, to Kth word. To do so, we need to calculate the dot product between this word (Word k) with each of the words of our sequence (Step 1), right? Oops…, ya asked why? Because as discussed earlier, the dot product is a measure of similarity based on what is happening at the heart of it! (refer to the inner product section if ya forget about why it’s happening).
Now, those inner products can be + (similar word) or — (dissimilar word). So, we exponentiate to make them positive with respect to preserving their meaning of them, right? (Step 2)
Then the last step is gonna be getting a relative representation of the strength of the inner product. So here, rk → i represents the relation of the Kth word to the ith word (Step 3) which represents the relative similarity of the word k to a word i. In other words, when we say relatively it means how much the Kth word is similar to the ith word, relative to the other words in the sequence! See the equation for the calculation of relative similarity!
relative similarity
The equation is;
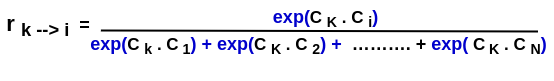
Note that r is always positive (because the exponentiate is always +) and it’s a number between 0 and 1 (reason will come along). So till now, we were able to quantify the relative degree to which, the Kth word is related to each of the N-words in the sequence. So the more related the Kth word is to any of the words in the sequence, the closer the r to 1 would be*(because they all add together)* and the more unrelated word is to each other, the closer to 0 is!