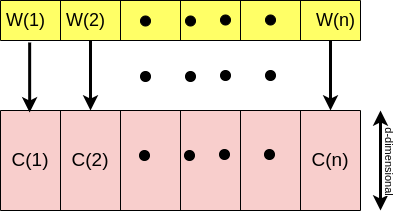
Now that we understand the concept of word2vec and the intuition beyond it, let’s move forward and generalize the same concept to a sequence of words. So based on our current knowledge, to get the words ready for further mathematical analysis and modeling, we map each word to a vector of d-dimensional, right?
v2w Diagram
As you probably notice, this way of mapping each word to a single vector is pretty restrictive 😐! Ya ask why? Imagine you have a dictionary book 📖, then you head to look for the word “bat” meaning. How many different meanings does it have? Doesn’t it rely on the concept that the word is in?

I’m pretty sure now that you understand why I said considering only a single vector per word is beyond restrictive because it does not take into account the surrounding words’ context! Therefore we need to build a framework by which, we can modify this mapping in a way that takes into account the meaning of surrounding words, right? 🌱 To do that, we need to first get familiar with the concept of Inner Product.
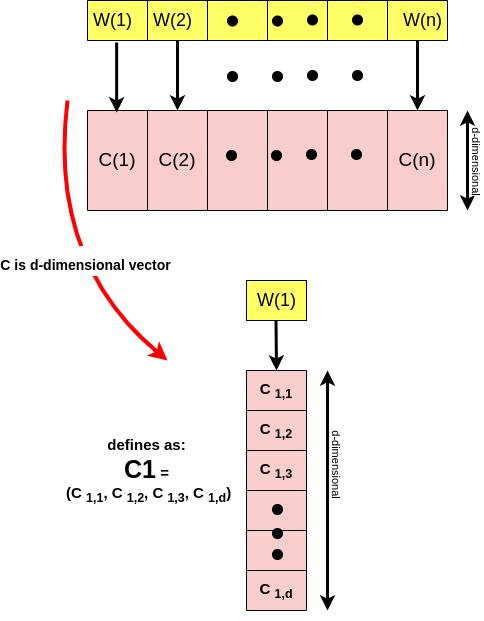
Remember I mentioned that within the concept of word2vec, we map each word to a vector of d-dimensional where each of those d-dimensional vectors is associated with a particular meaning/topic? Now keep reading👇
The purpose of the inner product is to quantify the relation/similarity between words! The way it does this is via taking the dot product of two vectors.
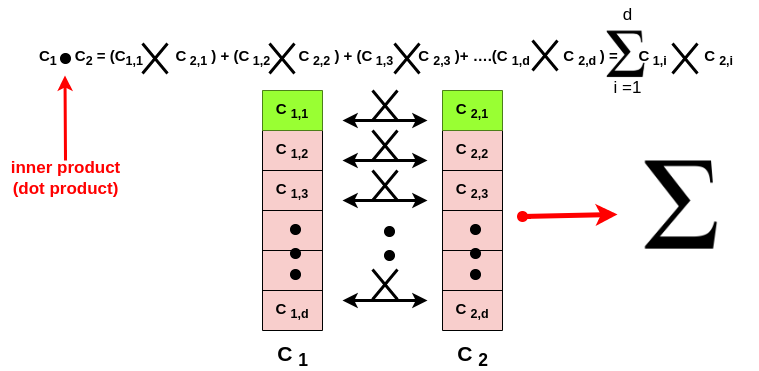
Here we have two vectors C1 and C2, each one of them has d-components. So we gonna take the first d-component of C1 and the first d-component of C2 and then multiply them together for all the d-components! After that, we sum all together which is the concept of inner product! So inner product is ****gonna;
Ya remember my notional example of Paris🗼? Now imagine we have two similar words; word1 and word2 which have 10-dimensional vectors associated with them (just for simplicity, in practice the dimension can get up to 256🤯*). When we say these words are similar then we know that their associated vectors gonna be similar, right? If yes, then it means that each of the components of the vector is similar(being either + or -)*! So in the below example, because these two-word vectors are similar, then as you see both the component 1st is positive!