Before deep-diving into 🏊♀️ Transformers, we need to first get familiar with the basic concepts of word embedding. The general idea of Word Mapping is that every word in our vocabulary is gonna be mapped to a vector!
But wait… What does it mean and how can it be done? 🤔 To understand the concept of word embedding, let’s just think of a map of the globe 🌎. In the following map is several different squares🟥, triangles🔺, and circles 🟣 (i.e. several locations 📍 throughout the 🌎). Now if you think about these locations in different parts, you probably agree that the regions which are geographically close to each other, have similar characteristics (e.g. similar culture, people, etc), and very different characteristics from the ones that are far away from each other! For example, we expect that the culture and lifestyle of the people living in Asia (🟣🟣) are similar to each other but very different from the ones in North America ( 🟥🟥), right?
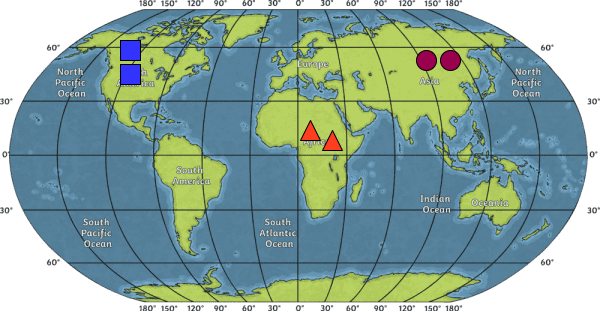
Location in world map
Now if we think of it from a math viewpoint by considering the latitude and longitude lines*(2D space)*, we can come up with the following idea:
So, we have a concept of Similarity manifested through Proximity, right? 🔥Now let’s see how can we relate what we have discussed*(similarity and closeness)* to the Word Embedding concept!👇
So pretty conceptually we can think of it as having a vocabulary of V words*(i.e. V1, V2, V3,….. V)*. Then think of mapping each word to a 2D space in longitude and latitude! So the way we would like to do this is to Learn the 2D vectors of the words in such a way that if two words are similar to each other, we would want their associated longitude and latitude to be near to each other and vice versa, right? That’s exactly the concept of Word Mapping!
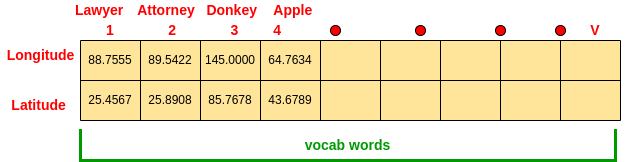
Word Mapping is the very fundamental block that we need to model our natural language. So make sure to understand it well. But the key 🔑 here to notice is that words are not numbers (i.e. they are not in form of numbers). However, for our mathematical Algorithms to be able to work and do analysis on our natural language words, they gotta be in form of numbers, right? Pretty the same as any other area in ML! This means that whenever we wanna do modeling of Natural Language, this modeling is achieved by Algorithms that potentially can work with numbers! So, what we need to achieve is a mapping of each word to a number, once achieved, then it’s ready for our algorithm for further analysis, right?
Now, the way we gonna do this is to map/relate every word in our vocabulary to ****a vector that may be more than 2D. But the idea is when the words are similar, they should be near/close to each other in the vector space and whenever they are dis-similar they gotta be far from each other(recall the 📍🌎 similarity conceptualization). Once we got this then with the concept of Learning we will learn the mapping of every word to a vector which will be discussed later in this article!
Each of the vectors associated with the given words is often called Embedding! The idea of Embedding is to map/embed the words to a vector space!